|
|
| Home > Index > Clustering > Geronimo Clustering with Gcache |
Gcache provides a generic caching framework suitable for many different uses. This article explores using Gcache as part of an overall clustering solution for Geronimo.
Here is a quick description of basic clustering concepts:
Gcache is a general purpose caching technology that can be used in a variety of environments. Though from the perspective of Geronimo clustering, Gcache will provide State Replication, Cluster Member discovery and Heartbeat. Note that other technologies can be used in conjuction with Gcache to support many of the other clustering concepts on the above list. The "Geronimo Clustering Setup" section below will provide more details on setting up the overall clustering environment.
The Gcache development is staged with the following priorities:
1) Clustering EJB artifacts (i.e. Stateful Session Beans and Entity Beans)
2) Web Tier clustering of httpsessions
The initial Gcache implementation for Geronimo provides a replicated cache that provides redundancy for state data.
The following diagram illustrates the cluster member discovery process as well as the heartbeat mechanism.
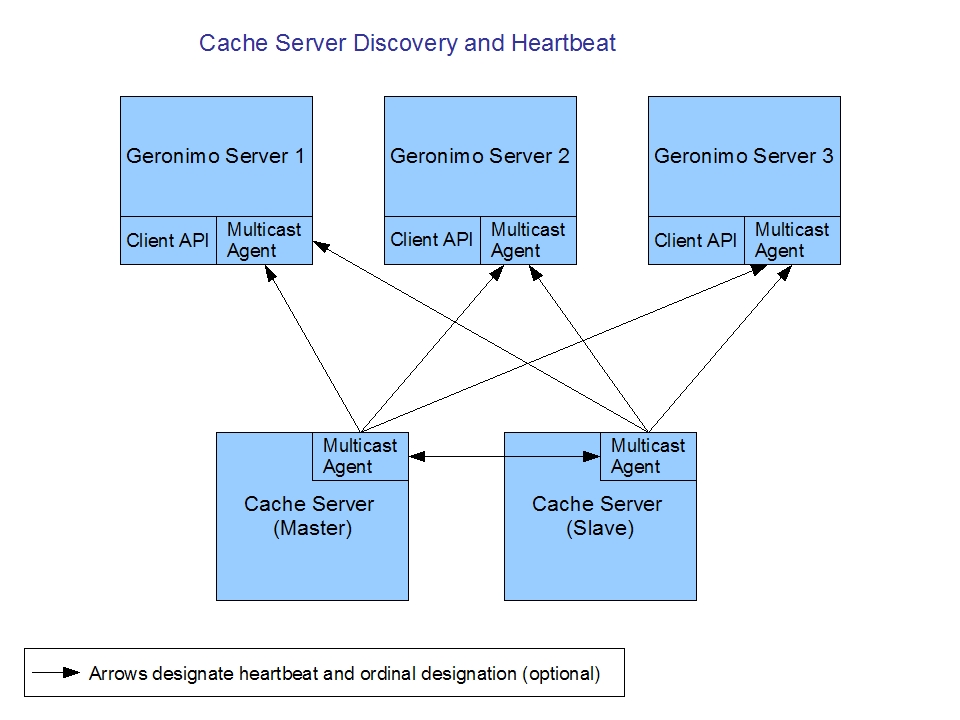
In this example, the Gcache server consists of a single master and a single slave process. Note that the topology
for the Gcache sever is quite flexible and allows for the Gcache server to either exist in the same physical machine and JVM
as the client or it can be a separate process on a different machine. For this example, we will assume the
Gcache server is a separate java process on a different machine.
Each Gcache server broadcasts its availability on a a pre-configured multicast address.
Optionally the Gcache server can also send a pre-configured ordinal value that denotes the relative priority of the Gcache server in the cluster.
Each client (in this case, a Geronimo server) listens for these broadcasts and keeps track of the available Gcache servers
as well as determining the current Master (the lowest ordinal value). Note that it is also possible to preconfigure the Gcache server ordinals in each client (Geronimo server).
When a client (Geronimo server) first arrives on the network, it makes a determination as to who the Gcache master is and authenticates itself with the Gcache server.
Whenever a cluster member needs to save state data (a.k.a session data), it communicates with the GCcache master
to save away it's state. This communication is provided in the geronimo server by the pluggable GCache Client API
that is leveraged whenever state data needs to be saved. <Add more details on pluggable Session Manager here>.
The diagram below shows the basic data flow associated with saving state data in the replicated Gcache server.
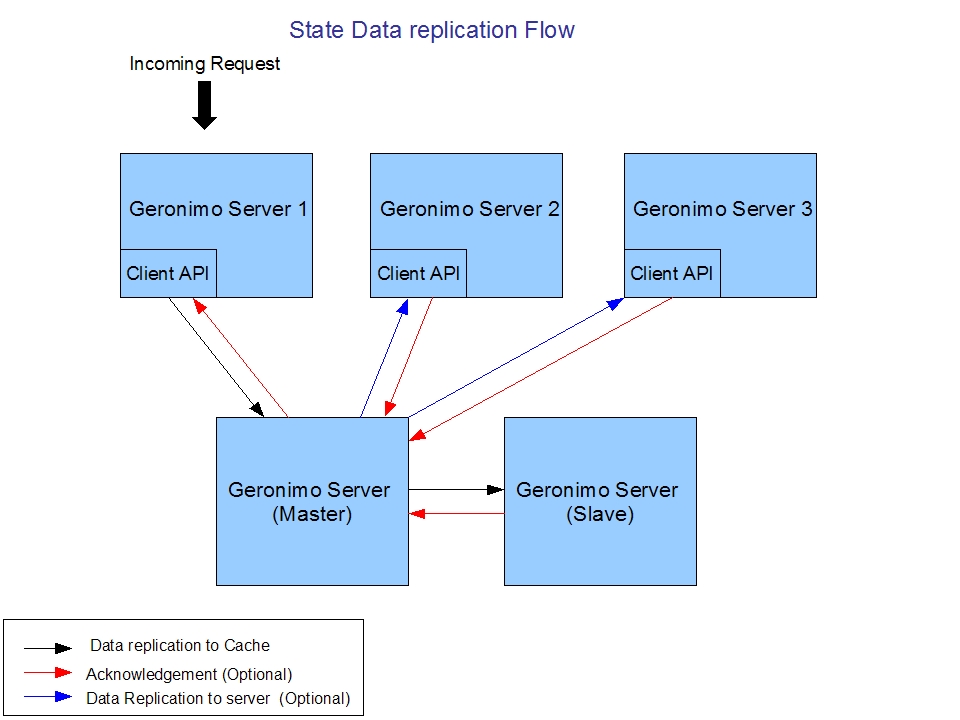
When the geronimo server decides that it needs to save session state, it will invoke the GCache client API
which will send the state data to the Gcache master. For added redundancy, the Gcache master will then replicate
this state to the Gcache slaves. Note that it is possible to optionally configure the Gcache server to send acknowledgements for
all data transmissions.
Also, the Gcache master can optionally send the replicated data to the other Geronimo servers in the cluster.
For clusters that do not have session affinity, this allows the state data to be immediately available in any
geronimo server that may get the next request for this data. However, this also has the disadvantage of
sending more data onto the network as well as increasing the memory usage for each cluster member since each cluster
member will contain all of the sessons in the cluster.
For clusters that can guarantee session affinity, it is possible to turn off the transmission of state data to the other
Geronimo servers and simply keep the state data only in the Gcache. This solution will cut down on traffic and
will likely scale better. If a cluster member were to fail, then sessions associated with that cluster member
would be failed over to a different cluster member. The new cluster member would be able to retrieve the necessary
session data from the Gcache.
Add the detailed setup instructions here
Add the specific steps here..
Add the details here..
|
|
Privacy Policy - Copyright © 2003-2011, The Apache Software Foundation, Licensed under ASL 2.0. |